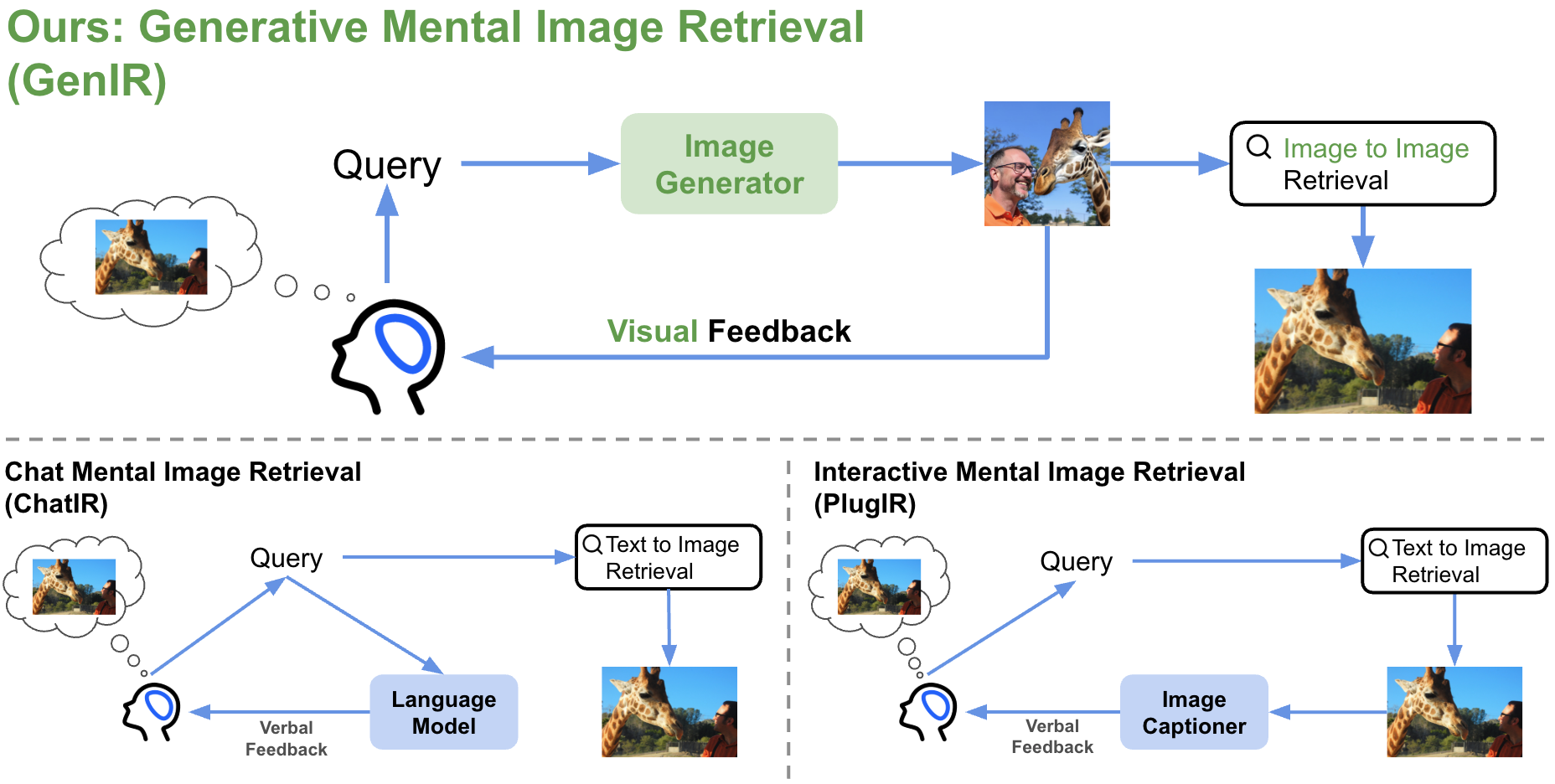
Vision-language models (VLMs) have shown strong performance on text-to-image retrieval benchmarks. However, bridging this success to real-world applications remains a challenge. In practice, human search behavior is rarely a one-shot action. Instead, it is often a multi-round process guided by clues in mind. That is, a mental image ranging from vague recollections to vivid mental representations of the target image. Motivated by this gap, we study the task of Mental Image Retrieval (MIR), which targets the realistic yet underexplored setting where users refine their search for a mentally envisioned image through multi-round interactions with an image search engine. Central to successful interactive retrieval is the capability of machines to provide users with clear, actionable feedback; however, existing methods rely on indirect or abstract verbal feedback, which can be ambiguous, misleading, or ineffective for users to refine the query. To overcome this, we propose GenIR, a generative multi-round retrieval paradigm leveraging diffusion-based image generation to explicitly reify the AI system’s understanding at each round. These synthetic visual representations provide clear, interpretable feedback, enabling users to refine their queries intuitively and effectively. We further introduce a fully automated pipeline to generate a high-quality multi-round MIR dataset. Experimental results demonstrate that GenIR significantly outperforms existing interactive methods in the MIR scenario. This work establishes a new task with a dataset and an effective generative retrieval method, providing a foundation for future research in this direction.
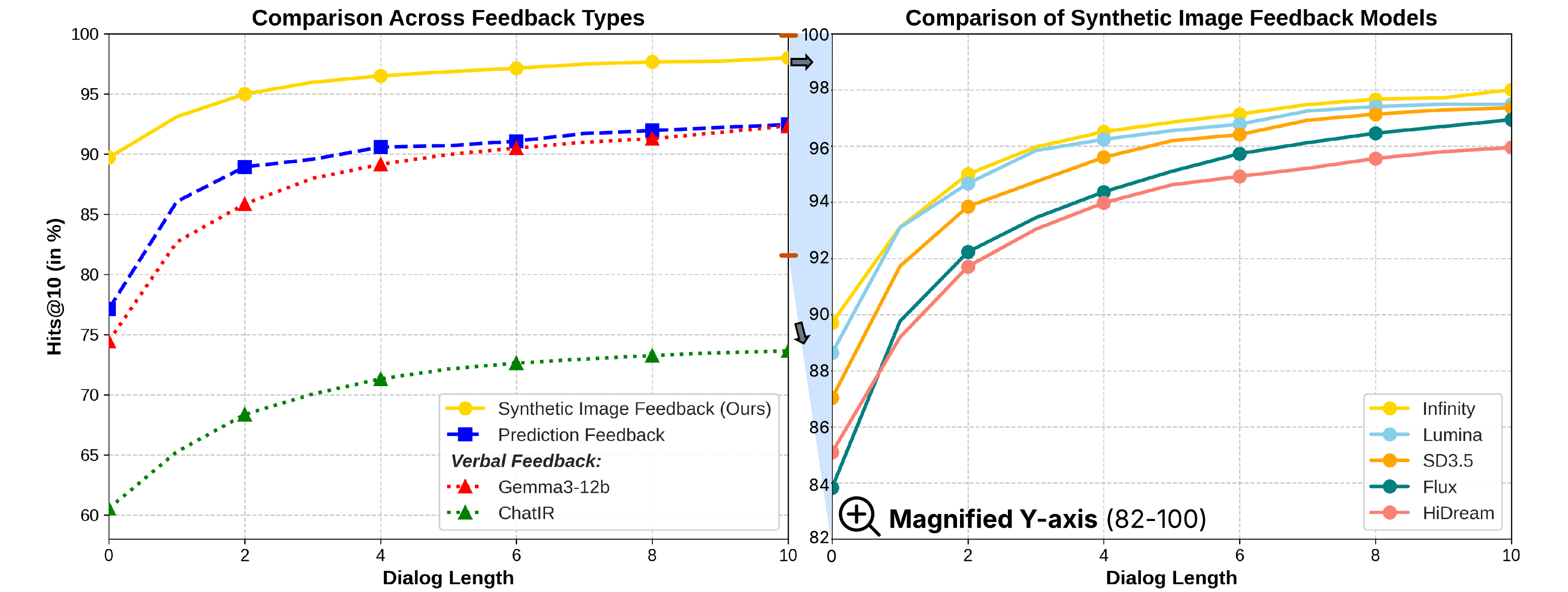
Performance Comparison on MSCOCO Dataset (Hits@10, 50k search space): Left: Our GenIR approach with Infinity diffusion model (Yellow) significantly outperforms all baselines, including Prediction Feedback (blue), Verbal Feedback with Gemma3-12b (red), and ChatIR with Text-based retrieval (green). Right: Comparison of different text-to-image diffusion models within our GenIR framework, showing consistent performance advantages across all generators.

Visual progression of GenIR's image refinement process: Each row shows the evolution from initial generation (leftmost), through multiple feedback iterations (middle columns), to final generated result, alongside the target image (rightmost). Note how generated images progressively capture more accurate details with each iteration—improving clothing and posture (row 1), facial features and giraffe positioning (row 2), and dining scene composition (row 3).

We introduce a fully automated pipeline to generate a high-quality multi-round MIR dataset. Each data point contains a target image and a 10 rounds of visual feedback in images together with a refined text query.
@article{yang2025genir,
title={GenIR: Generative Visual Feedback for Mental Image Retrieval},
author={Yang, Diji and Liu, Minghao and Lo, Chung-Hsiang and Zhang, Yi and Davis, James},
journal={arXiv preprint arXiv:2506.06220},
year={2025}
}